Abstract
Building generalist robotic systems involves effectively endowing robots the capabilities to handle novel objects in an open-world setting. Inspired by the advances of large pre-trained models, we propose Keypoint Affordance Learning from Imagined Environments (KALIE), which adapts pre-trained Vision Language Models (VLMs) for robotic control in a scalable manner. Instead of directly producing motor commands, KALIE controls the robot by predicting point-based affordance representations based on natural language instructions and visual observations of the scene. The VLM is trained on 2D images with affordances labeled by humans, bypassing the need for training data collected on robotic systems. Through an affordance-aware data synthesis pipeline, KALIE automatically creates massive high-quality training data based on limited example data manually collected by humans. We demonstrate that KALIE can learn to robustly solve new manipulation tasks with unseen objects given only 50 example data points. Compared to baselines using pre-trained VLMs, our approach consistently achieves superior performance.
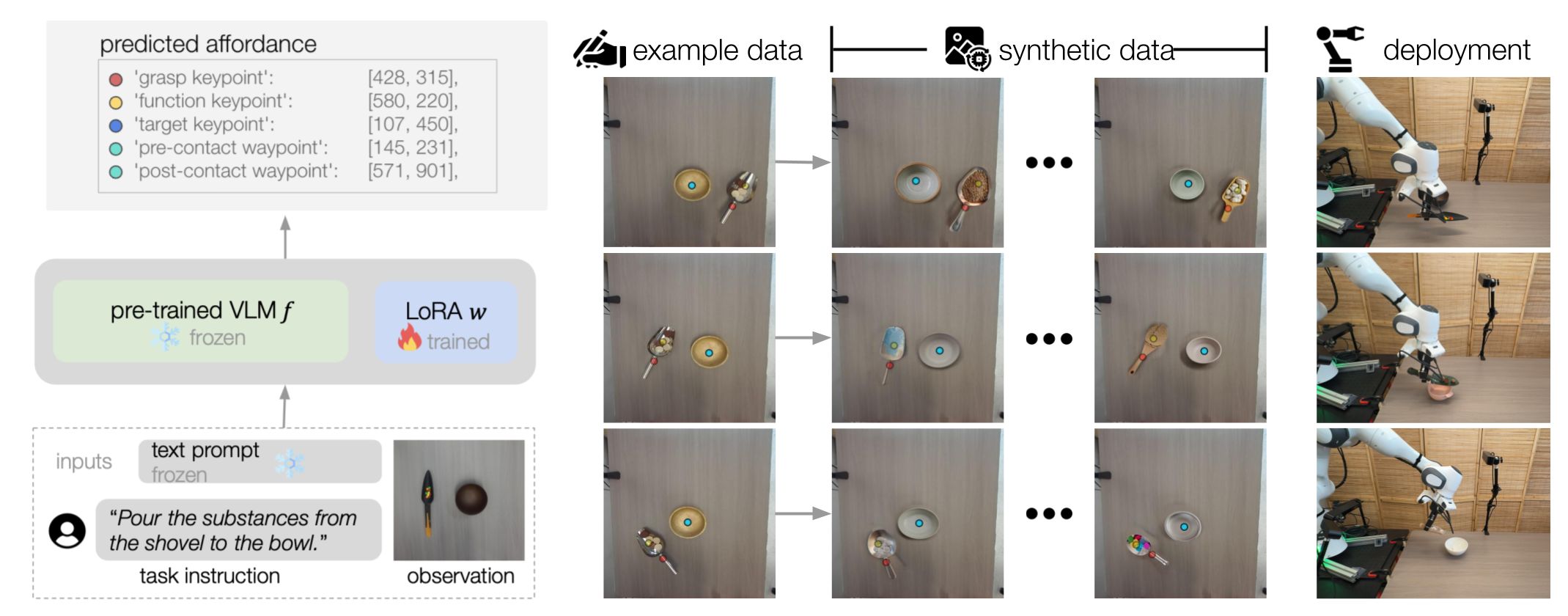
Keypoint Affordance Learning from Imagined Environments (KALIE)
By fine-tuning a pre-trained VLM, KALIE predicts the point-based affordance representation given the observed image, the task instruction, and a text prompt. The point-based affordance specifies the desired motion to complete the task.
Starting with limited example data collected from the real world, KALIE generates synthetic data with high diversity and quality, while preserving the task semantics and keypoint annotations. The fine-tuned VLM can robustly generate motions unseen objects and scene arrangements.
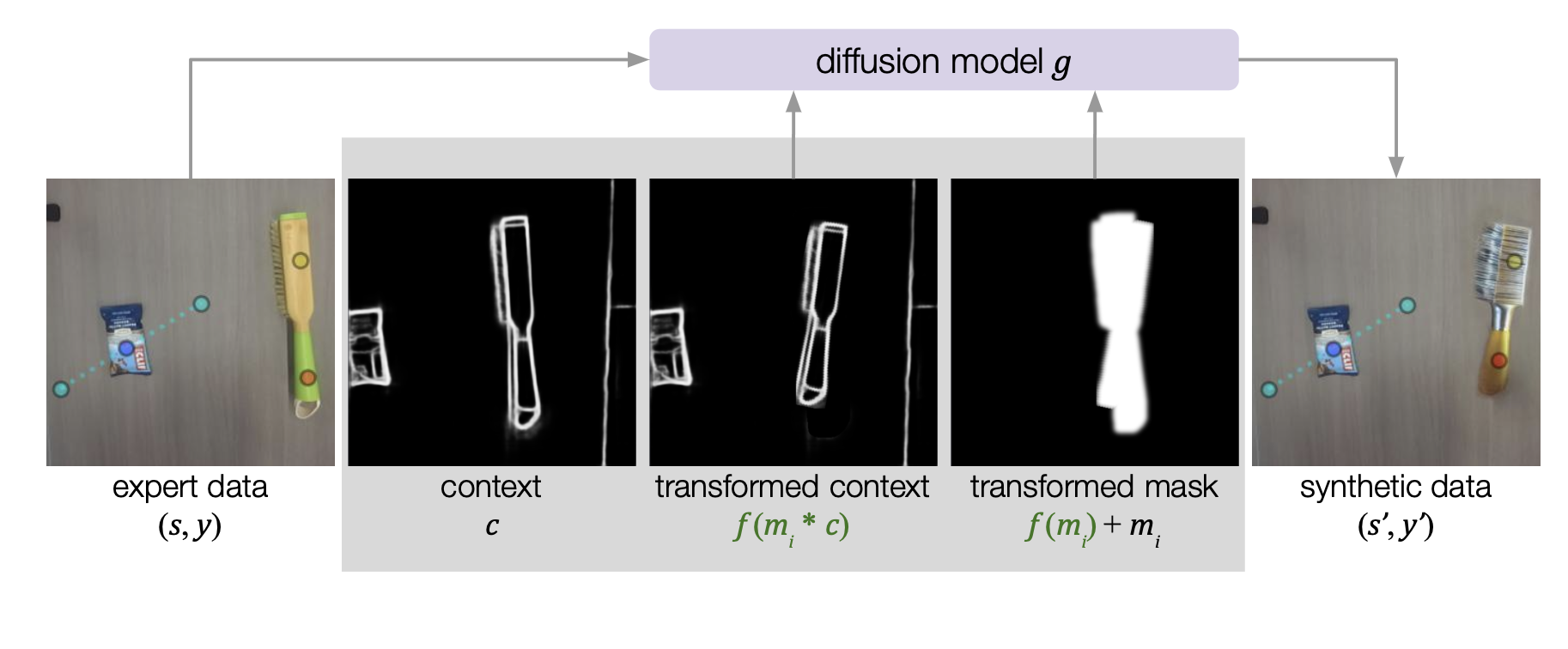
Affordance-Aware Data Synthesis
KALIE employs the inpainting capability of a pre-trained diffusion model to generate synthetic data. To diversify the scenes while staying faithful to the task semantics and the keypoint annotations, KALIE uses a context image as additional inputs to the diffusion model, which specifies the geometric properties of the object to be inpainted. The context image is computed from the original RGB image and can be randomly transformed to further diversify the synthetic data.
Synthetic Data
KALIE diversifies the shape, texture, and poses of the objects in the environment. Below, we progressively change the transformation parameters of the context and the input noises to the diffusion model to show the diversity and quality of the synthetic images.

In each column, we show example synthetic images generated based on two example images respectively for the same task. The original and transformed point-based affordances are plotted on top of the images.

Task Execution
KALIE can solve manipulation tasks involving diverse unseen objects and initial arrangements.
Sweep the trash off the table
Close the drawer
Hang the towel on the rack
Pour small objects into the bowl
Unplug the USB stick from the laptop